오늘의 공부: 3-6장부터 3-10장까지
– 미니 배치 SGD
-순간
-RMSProp
– Adam(적응 모멘트 추정)
– 교육, 검증, 테스트 데이터
– K-겹 교차 검증
어제에 이어 장의 내용을 계속하겠습니다. 이번에는 어제 조사한 SGD를 더욱 완화합니다. Mini-Batch는 mini-batch를 통해 단일 오류에서 mini-batch 크기만큼 큰 하이퍼파라미터를 사용하여 SGD를 튜닝 가능하게 하여 GD의 문제를 어느 정도 수정합니다. SGD 방향을 “완전히” “부드럽게” 만드는 방법과 마지막으로 RMSProp을 통해 방향을 평준화하는 방법을 배웁니다. 이 모든 것을 결합한 옵티마이저는 Adam이며 다른 많은 옵티마이저가 있습니다. 참고로 옵티마이저는 손실 함수의 구현으로 볼 수 있습니다. 손실 함수는 집합적인 용어이며 옵티마이저의 특정 구현이 필요합니다. 알고리즘적으로 말하면 힙은 우선 순위 대기열의 구현입니다.
결론적으로 오늘 우리는 옵티마이저, RMSprop, Adam 등의 순간을 알게 될 것입니다.

까지…
1. 미니 배치 SGD:
오늘 나는 Andrew Ng의 Coursera 과정에서 Mini-Batch를 구현한 것을 기억한다는 것을 깨달았지만 Mini-Batch가 왜 필요한지 확신할 수 없었습니다. 미니 배치를 사용하면 운동 중에 서버 전원이 꺼지더라도 훈련된 웨이트가 자동으로 저장될 줄 알았는데… 역시 안되더라구요!
기존 GD는 모든 오류를 계산하여 계산 속도가 느려지는 문제가 있었지만 SGD는 단일 오류를 손실로 사용하므로 방향이 위아래였습니다. Mini-Batch SGD는 개별적으로 이 오류를 1이 아닌 batch_size로 설정합니다. 따라서 batch_size = 3이면 “bag”에서 3개의 오류를 빼서 손실을 계산하고 방향은 3개의 오류를 고려한 방향이므로 확실히 덜 바운스됩니다. 개인보다.
여기서 주의할 점은 batch_size가 너무 크면 학습 속도가 급격히 떨어지기 때문에 결국 mini-batch를 사용하는 이점이 사라지는 시점이 온다. 따라서 batch_size가 두 배가 되면 학습률도 두 배가 되어야 합니다. 이를 선형 스케일링 규칙이라고 합니다.
2. 모멘트 + RMSProp = 아담
인트로에 첨부된 이미지를 보면 SGD의 옵티마이저는 단계 방향(하늘색)과 단계 크기(분홍색)의 두 가지 색상으로 나뉩니다. 순간 걸음 방향을 진정시킵니다. 물론 방금 언급한 mini-batch도 역할을 하지만 batch_size에 따라 효과가 그리 안심되지 않을 수 있습니다. 그래서 Moment는 애초에 나태함을 손실로 돌리는 철학을 가지고 있습니다. 이 손실의 계산은 이전 손실의 약 1/2에 영향을 받아야 하지 않습니까? 맞아요 사실 수학공식으로 표현하면 복잡하지만 실제적인 의미나 계산은 비슷해요.
그리고 ML에서 흔히 말하는 안장문제(saddle problem)가 있는데 모멘텀은 그 문제를 잘 극복하고 있다. 이전 손실을 전혀 사용하지 않고 미니 배치를 사용하지 않는 SGD는 단순히 불안정한 평형 상태에서 멈춥니다. 하지만 모멘텀은 이를 극복하고 더 낮은 손실 위치로 향하고 있습니다.
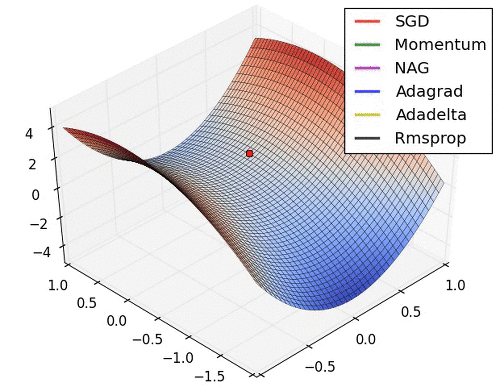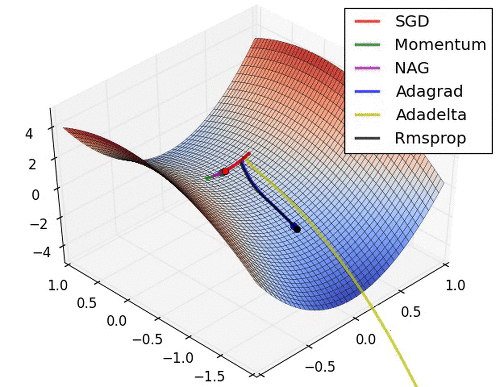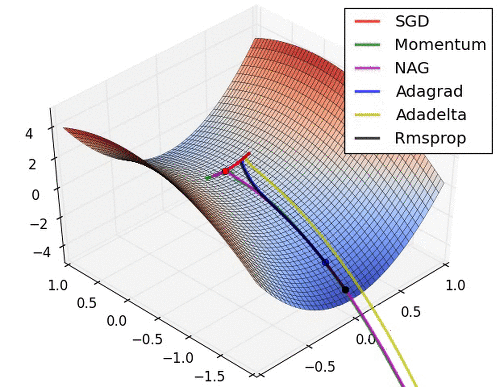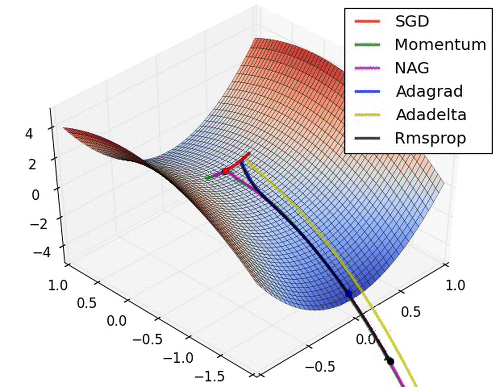
단계 방향이 정리되었으므로 이제 단계 크기도 조정해야 합니다. 단계 크기는 RMSProp을 사용합니다. 솔직히 공식이 잘 이해가 안되지만 직감적으로는 단순히 벡터인 손실의 수를 보상을 위한 정제에 주는 것입니다. 그 효과는 가파른 경사면에서는 느리게 가고 가파른 경사면에서는 빠르게 가는 경향이 있어 안장 문제를 해결하는 데에도 도움이 됩니다.
Adam(적응적 모멘트 추정)은 모멘트와 RMSProp의 조합입니다. GD와 SGD의 약점을 한 방에 노리기 때문에 매우 자주 사용된다고 한다.
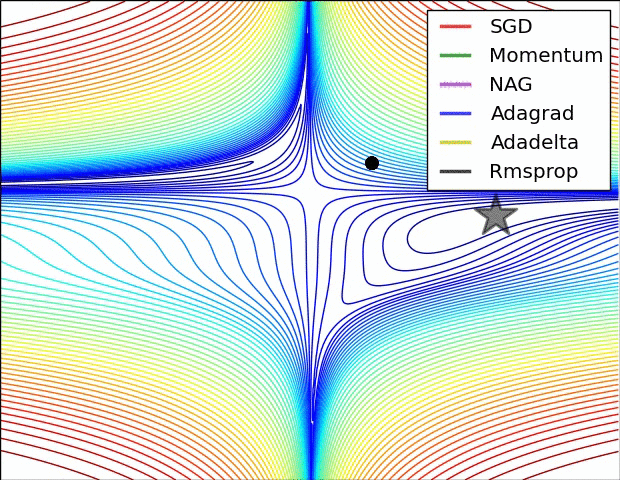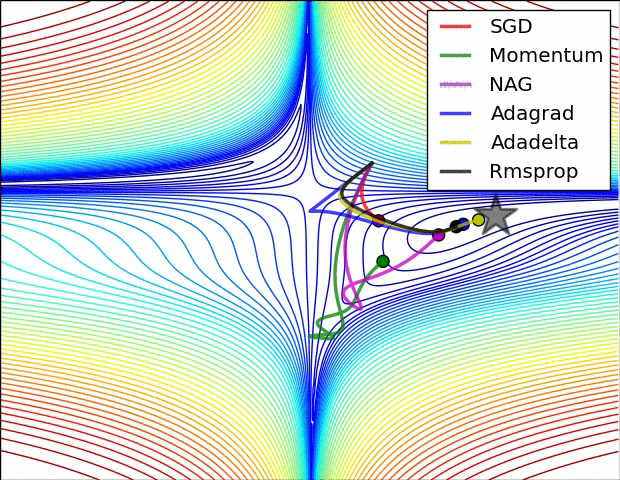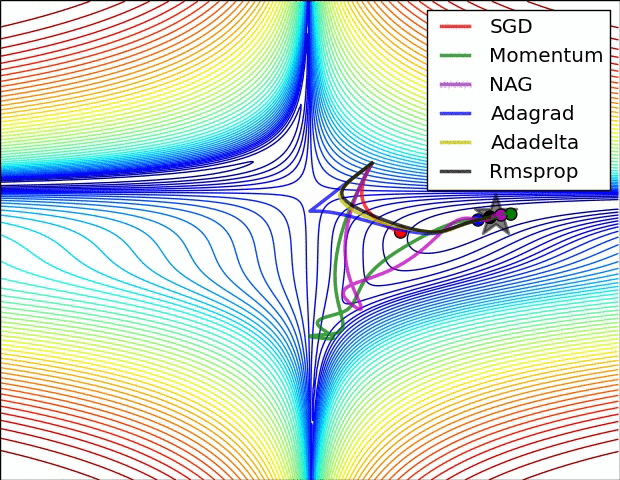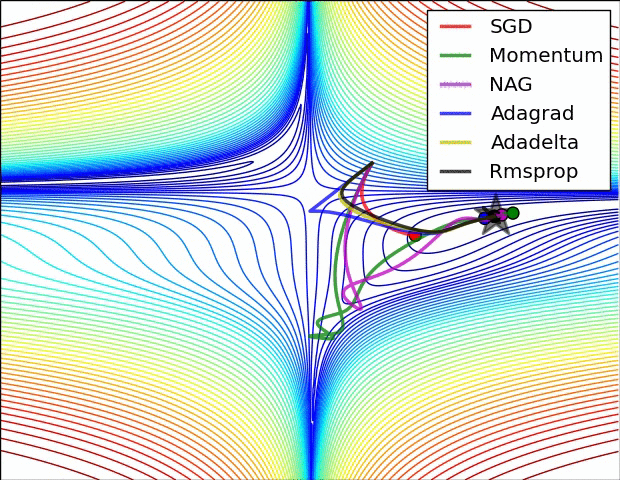
3. 교육, 검증, 테스트 데이터 세트, k-겹 교차 검증
훈련 데이터는 훈련 문제입니다. 학생들은 교과서를 읽고 연습을 합니다. 유효성 검사는 모의 테스트입니다. 유효성 검사 데이터는 훈련 데이터에서 소수를 선택해야 합니다. 하이퍼파라미터 튜닝은 검증 데이터로 수행되기 때문에 그 중요성도 똑같이 중요합니다. 검증 데이터에 편향이 있는 경우 어떤 최적화도 시간 낭비일 수 있으므로 k-겹 교차 검증 기법을 사용하십시오.
예를 들어 동물 이미지를 분류하는 DNN을 구축하고 있습니다. 아무것도 모르고 마지막 50장의 사진에 인증 날짜를 적습니다. 하지만 사진 데이터는 버릇없으며 사진 목록은 고양이 1-100, 개 101-200, 코끼리 201-300이다. 그러면 validation set이 251~300이 되므로 실제 validation 과정(mock validation)을 수행할 때 코끼리 이미지만 평가하고 하이퍼파라미터는 코끼리 분류만을 위한 것이기 때문에 재난 위험을 피할 수 있다.


2 테스트 녹음: 강의 노트 만들기
패스트 캠퍼스: http://bit.ly/3Y34pE0
공백 없음: 2313자
감사해요